Over the past few months I've watched the same thing happen again and again: sharp engineers discover Claude Code sub-agents, get excited, and describe them as a way to make specialists — a GPU engineer, a security reviewer, a docs writer. That framing undersells them, badly.
The real win isn't the job titles. It's that sub-agents give Claude a place to do the messy, expensive, tool-heavy work somewhere else. They can search, grep, read docs, chase dead ends, run commands, and sometimes burn tens or hundreds of thousands of tokens — without dragging the intermediate debris into your main session. You get the useful part back, not the entire junk drawer.
I'll admit I was slow to say this out loud. I'd been using sub-agents for months (the idea came from a LinkedIn post about keeping a repo of role-based agents), and I noticed early that each one ran off on its own — Claude Code even started showing little colored labels as it spun them up in parallel. When I mentioned the context angle to people, they mostly shrugged: "yeah, of course." But it wasn't obvious, and most of them hadn't pictured what it actually implies. So here's the picture.
Why this matters: long sessions rot
A normal Claude Code session is one thread — one context window, one conversation. And the longer that thread gets, the worse the model does — not only when you blow past the window, but well before it. A 2025 paper, Context Length Alone Hurts LLM Performance Despite Perfect Retrieval (Findings of EMNLP), found accuracy dropping 14–85% from length alone — even with perfect retrieval and nothing distracting in the window. Chroma's Context Rot report saw the same across 18 frontier models, Claude included; it's an old observation (the 2023 "lost in the middle" work) that newer results keep confirming.
A Claude Code session isn't a benchmark prompt, but it creates the same underlying pressure: more accumulated tokens, more irrelevant residue, more chances for the detail that matters to get diluted. The usual mitigation is compaction — summarize the session so far and start over — but compaction is a band-aid; Anthropic's own context-engineering write-up is candid that it's inherently lossy. And the biggest contributor to the whole problem is tool output: a single file read, a grep dump, or a verbose command result can be thousands of tokens, and in a normal session they pile up fast.
The picture
Sub-agents change the shape of the work. Instead of one increasingly polluted thread, you get a coordinator and a set of isolated scratchpads: the main session decides what matters, the sub-agents do the noisy exploration, and when they finish the parent gets back only their final message — a compact result, not the grep dumps, command output, failed branches, and docs spelunking that produced it. You're not making one context window bigger; you're keeping the expensive thinking out of the room where decisions happen. (It's the same move Anthropic recommends in that write-up — focused sub-agents in clean windows, handing summaries back to the parent.)
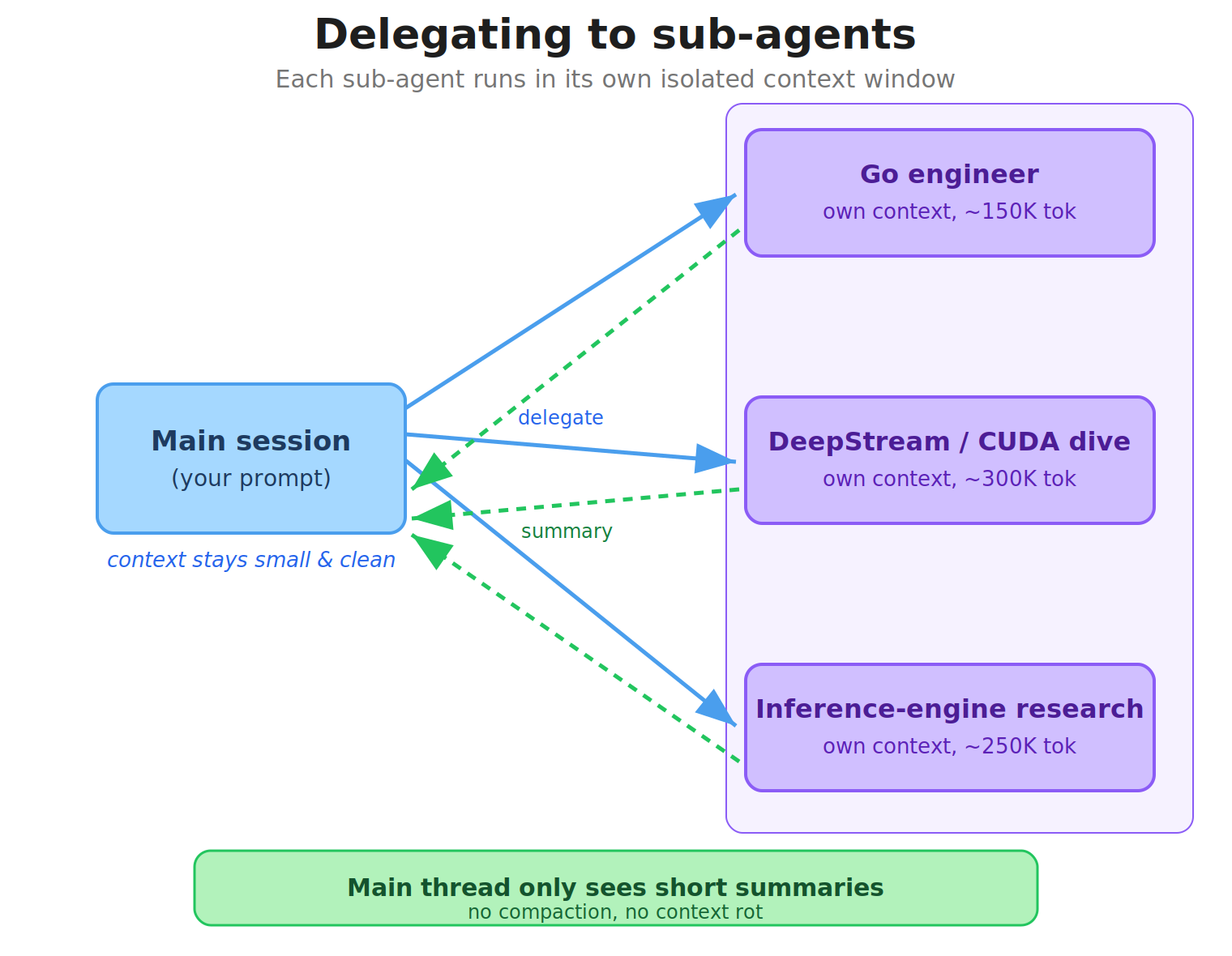
What it actually feels like
The benefit didn't fully click for me until I noticed the absence of something: I'd stopped hitting compaction. Whole stretches would go by — days, sometimes a week or two on the same main session for a project — without Claude ever pausing to summarize and reset. All the expensive, context-hungry work was living inside sub-agents, so the main thread just never filled up. I'd glance down mid-project and still be sitting at half my context.
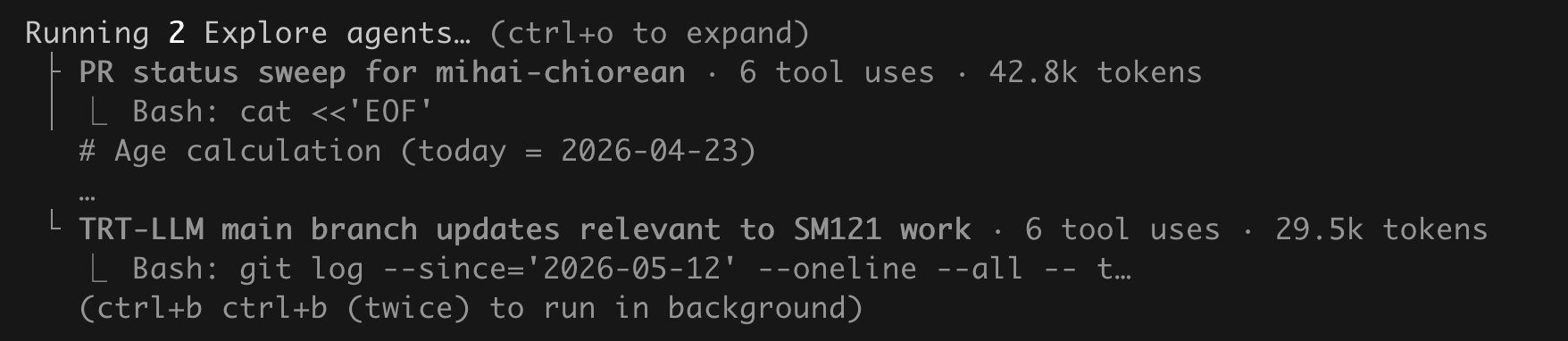
Two concrete examples.
I needed a Go library to be extremely efficient for a vision pipeline, so I handed it to a Go specialist with the Effective Go principles in its prompt: cut allocations, revisit the concurrency model, write allocation benchmarks. It got the hot path to zero allocations per op — a million samples through the pipeline now produce 33 heap allocations total, roughly one per 30,000 samples, so effectively no GC pressure on a long-running stream. One concurrency fix alone — splitting a contended mutex — took a hot benchmark from 230 ns and 5 allocations per op down to 75 ns and zero, and it left behind benchmarks that fail CI if the allocations ever creep back. And the benchmark runs, the failed approaches, and the source spelunking that produced all of it never touched my main thread.
Same with the NVIDIA / JetPack work, which is a rabbit hole by nature: which JetPack version, which DeepStream, which TensorRT path, which container-runtime quirks, which NVIDIA libraries are actually present on the target image versus assumed by the examples. I send a sub-agent in with a high-level prompt, let it map the terrain, and get back a course of action. Before this, every one of those digs meant hitting compaction, over and over.
(Recent Claude Code versions also improved the /agents UI: its Running tab shows live sub-agents and lets you open or stop them, which is probably why more people are noticing the feature now.)
How to start tomorrow
You don't need 70. Start with five:
code-reviewer, debugger, performance-engineer, researcher, test-runner.
There's plenty to configure on a sub-agent — tools, model, permissions, max turns, whether it can write files. But for routing and context hygiene specifically, two things matter more than people expect:
- Write a narrow description. Claude decides when to delegate based on the agent's
descriptionfield. Job-shaped names liketest-runnerorrepo-explorerroute far more reliably than vague ones likefrontend-engineer, which sound flexible but give Claude a weaker signal. - Tell each agent what to return. The output format isn't cosmetic — it's the valve that controls how much context leaks back into the main thread. "Return a prioritized list, each item with
file:lineand a one-line fix" keeps the summary tight; "explain what you found" invites a flood.
Then delegate explicitly: tell Claude to send the messy part to a specialist and keep the main thread for decisions. (I still ask for this on most prompts — I know, I know, it's clumsy. The plan is to bake "delegate the noisy work" into project instructions so it becomes the default instead of a request.)
How I organize mine
Once I'd grown to ~70 agents, I had a new problem: too many possible specialists loaded everywhere. So I split them by where they belong. A small user-level set lives in ~/.claude/agents/ and is available in every project — the handful that genuinely fire everywhere (a tech-lead, a reviewer, my blog-writer). Everything else lives in a separate repo called inc. The joke is that it's the HR department for a small fake company: the agents live there, and a little staff skill reads a project's README/CLAUDE.md and stages only the relevant subset into that project's own .claude/agents/. The principle is simple: don't carry every specialist into every session.
~/.claude/agents/ # user-level: the few I want in every project
├── tech-lead.md
├── code-reviewer.md
└── blog-writer.md
my-project/
└── .claude/
├── agents/ # staged by `staff` — only what this project needs
│ ├── go-engineer.md
│ └── vision-engineer.md
└── staff/lock.yaml # which agents are staffed, pinned to a version
When the HR repo changes, staff sync reconciles each project against it. The full machinery — the manifest, the matching hints, the sync/overlay flow — is in the repo if you want it.
A few caveats
- You're not saving tokens. This is the one people get wrong: sub-agents don't make exploration free, they spend the tokens somewhere more contained. It's a context architecture, not a token hack — you protect the main thread, you don't shrink the bill.
- Disk edits need a restart. If you add or edit agent files directly on disk, restart Claude Code for them to load. Agents created through
/agentsapply in-session. My staff flow writes files directly, so I still do the/exit→claude --resumedance. - More agents isn't better. Past a point they add overhead and make routing less predictable — which is the whole reason for staffing a subset. Claude Code will actually warn you when the roster gets too large; that warning is what pushed me to build this in the first place.
- A sub-agent can still pollute the main thread if it hands back too much. The summary discipline lives in the description; if you don't constrain the output, the spam comes home.
- Not every task deserves one. Reach for sub-agents when the work is noisy, uncertain, parallelizable, or tool-heavy. A two-line change doesn't need a committee.
The actual mental model
The mistake is thinking of sub-agents as a way to give Claude cute job titles. They're better understood as disposable, isolated workspaces for expensive thinking — somewhere to do the noisy, uncertain, tool-heavy parts of a task while the main thread stays clean for decisions, synthesis, and direction.
Work that way for a while and Claude Code stops feeling like one increasingly tired conversation and starts feeling like a small team that does its messy work somewhere else and hands you back the part that matters. For me the practical payoff is simple: unfamiliar projects feel less brittle — I can send a specialist to map the terrain before I start changing anything.
The repo's public if you want to lift the pattern: github.com/mihai-chiorean/inc. It's opinionated and still evolving, but it's the system I actually use.